
CodeMirror 是一款优秀的开源文本编辑器,常用于代码编辑器。但并不支持富文本编辑功能。但是得益于 CodeMirror 的 API
markText: Can be used to mark a range of text with a specific CSS class name.
能够为指定 range 的文本设置一个 CSS class,这样我们就可以通过这个 class 来设置富文本样式。例如对于文本:ABCDEFGHF,我们可以通过如下方式为其设置 class

markText 方法会返回一个 CodeMirror.TextMarker 对象,该对象中的 clear() 方法用于清除 class,这样就非常便于我们动态为文本设置富文本样式了。
为了管理,操作整个富文本文档流,我们引入 AnnotationList 单链表结构,把每一段富文本当成 Node 节点,由此形成链表结构。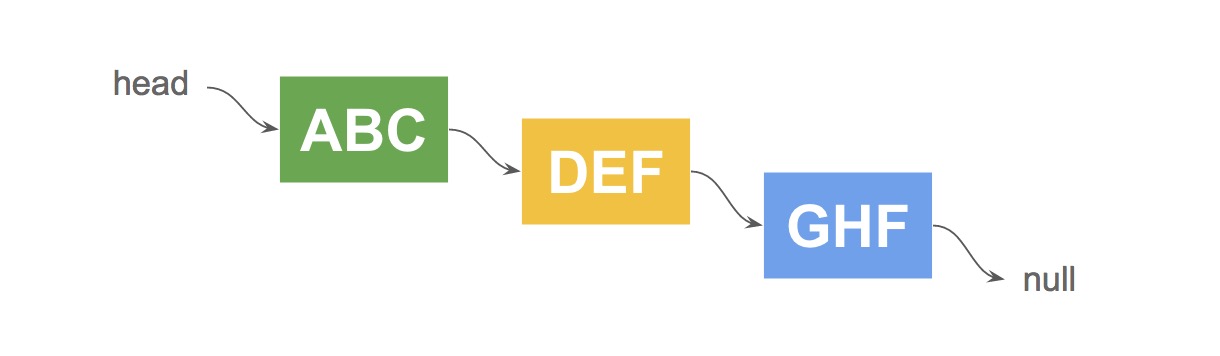
本文将详解 AnnotationList 单链表结构 🤓
文本区间 Span 类
|
|
Span 表示一段文本区间:
pos:区间起点length:区间长度(若长度为0,即未选中文字,只表示光标位置)
链表节点 Node 类
|
|
链表节点包含四个属性:
length:表示该节点的文本的长度,需要注意的是,节点并不需要直接存储文本内容annotation:表示节点包含的富文本属性attachedObject:CodeMirror.TextMarker对象next:指向下一个节点
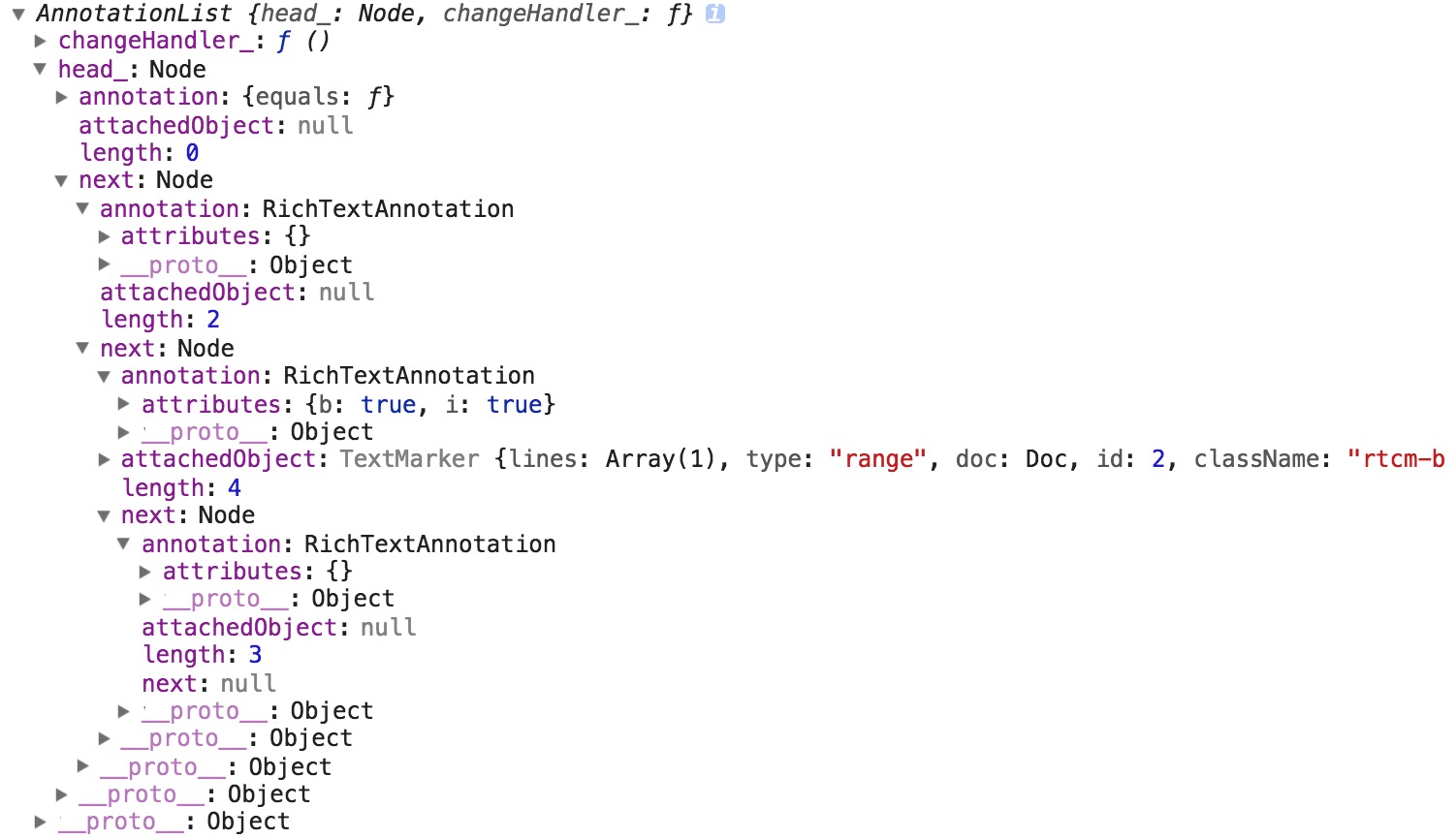
辅助方法 getAffectedNodes_(span)
此方法用于获取指定文本区间(span)在单链表中的节点信息,包括:
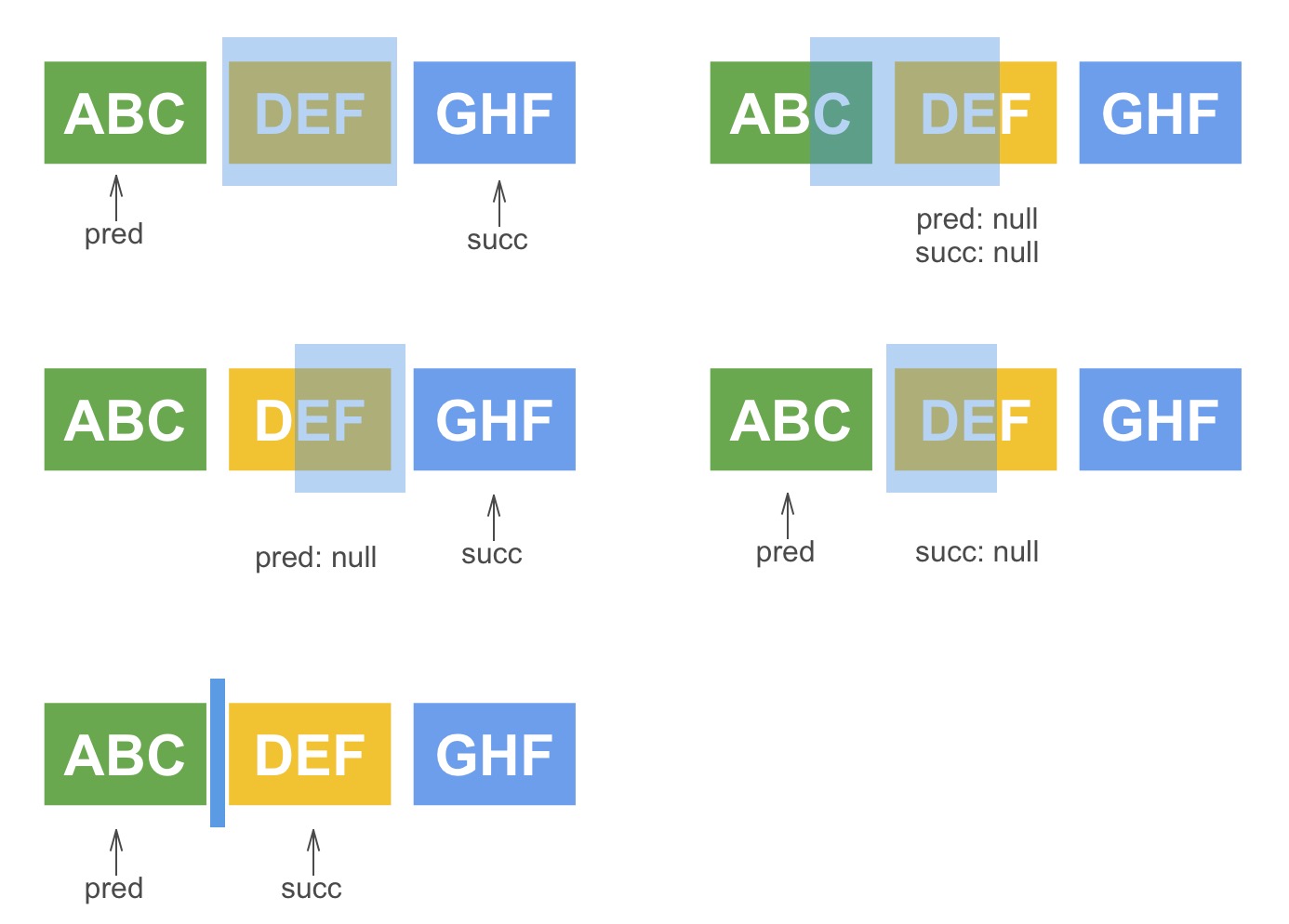
start: the node contains the first character in span.end: the node contains the last character in span.beforeStart: the node beforestartnode.succ: the node afterendnode ifspan.end()was on a node boundary, elsenull.pred: the node beforestartifspan.poswas on a node boundary, elsenull.beforePred: the node beforeprednode.startPos: the position ofstartnodepredPos: the position ofprednode
start 和 end
start 和 end 分别表示文本区间(span)的第一个和最后一个字符所在的节点。
大致有如下三种情况:

pred 和 succ
pred 和 succ 是指文本区间(span)左右边界恰好也是处于单链表节点边界处时,左边界的前一个节点和右边界的后一个节点。
大致有如下五种情况:
startPos 和 predPos
startPos 和 predPos 是指 start 和 pred 节点首字符在整个文档中的位置
链表操作
文档编辑过程中的富文本操作对应到单链表中的操作包括增删改查,其中插入,删除和更新,这些方法都依赖这个方法:
其中 span 指定文本区间;而 operationFn(res.startPos, res.start) 回调方法根据从辅助方法 getAffectedNodes_(span) 获取的 startPos, start 信息生成一段新的链表段。wrapOperation_ 将新生成的这段链表融入到原有的 AnnotationList 单链表。
插入操作 insertAnnotatedSpan
插入操作包括两种情况:
其中前者在节点间隔处插入,start 节点为 null,此时由新插入的文本生成 Node 节点作为新生成链表段直接返回;而后者在节点中插入,start 节点为当前节点,生成新链表段需要将 start 节点从插入点分裂生成两个节点,新插入的文本作为新 Node 节点插入其中,如下图所示: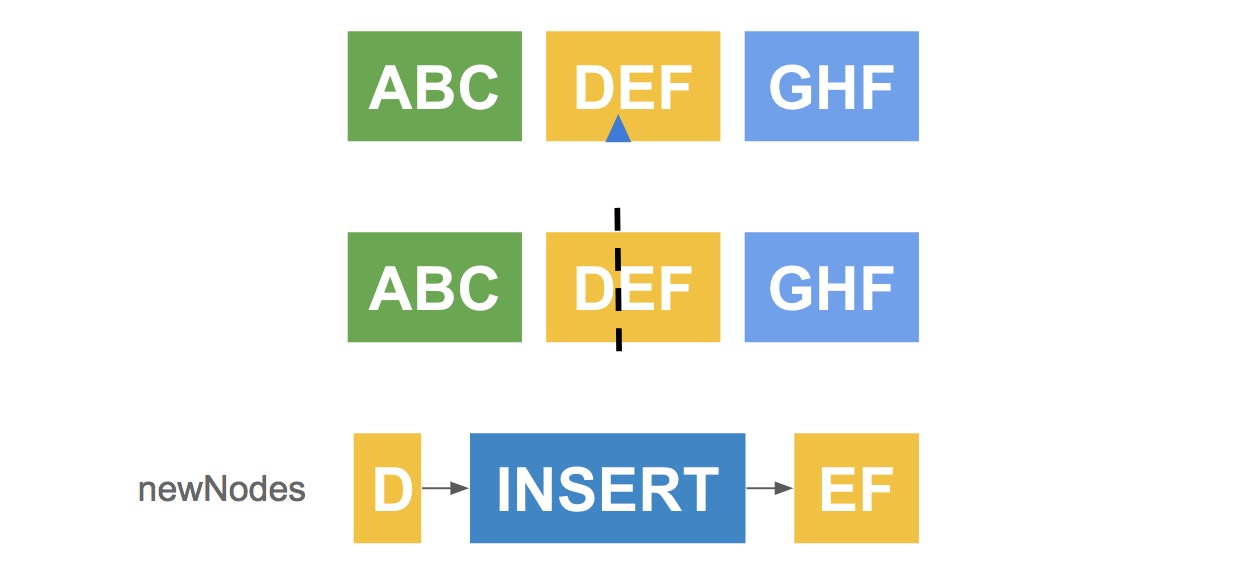
|
|
删除操作 removeSpan
删除操作中,要求文本区间长度大于 0;其执行过程如下图所示: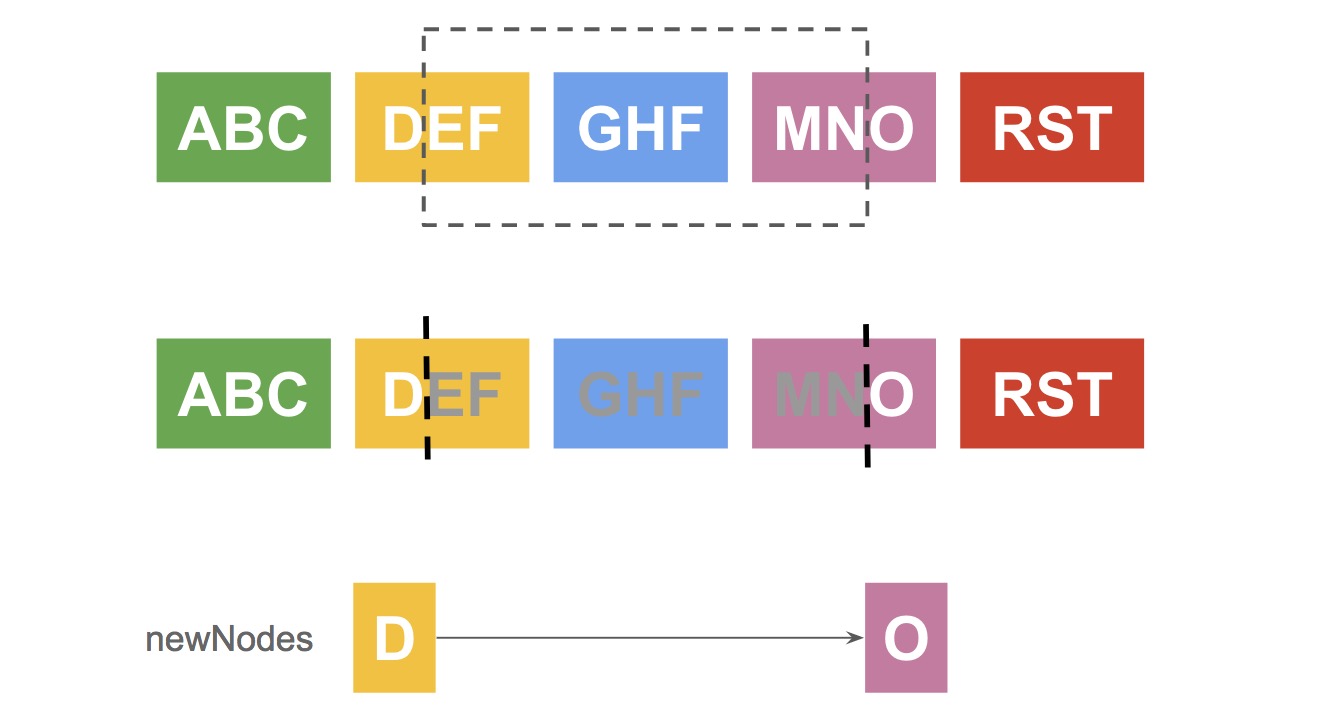
|
|
更新操作 updateSpan
更新操作中,文本区间长度也要大于 0;其执行过程如下图所示: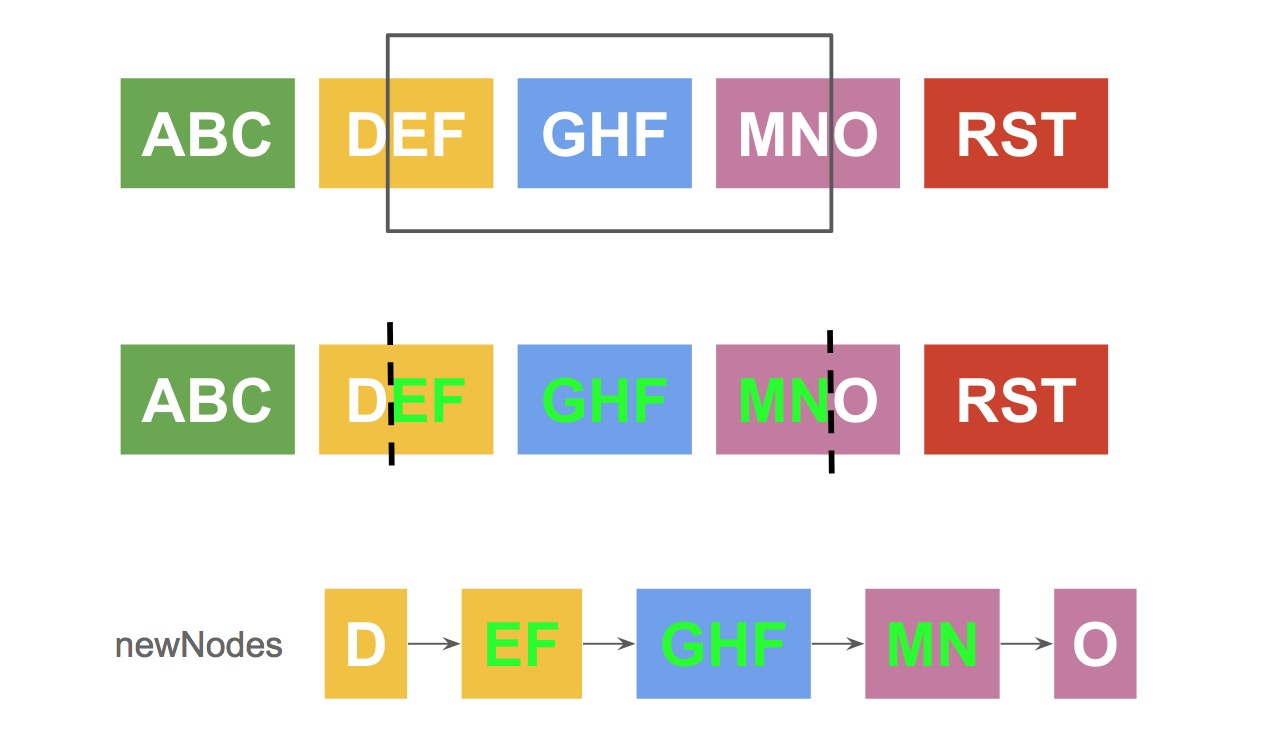
|
|
wrapOperation_
wrapOperation_ 方法是 AnnotationList 链表操作的核心方法,通过这个方法会从单链表中提取需旧节点数组和新节点数组,如下图所示: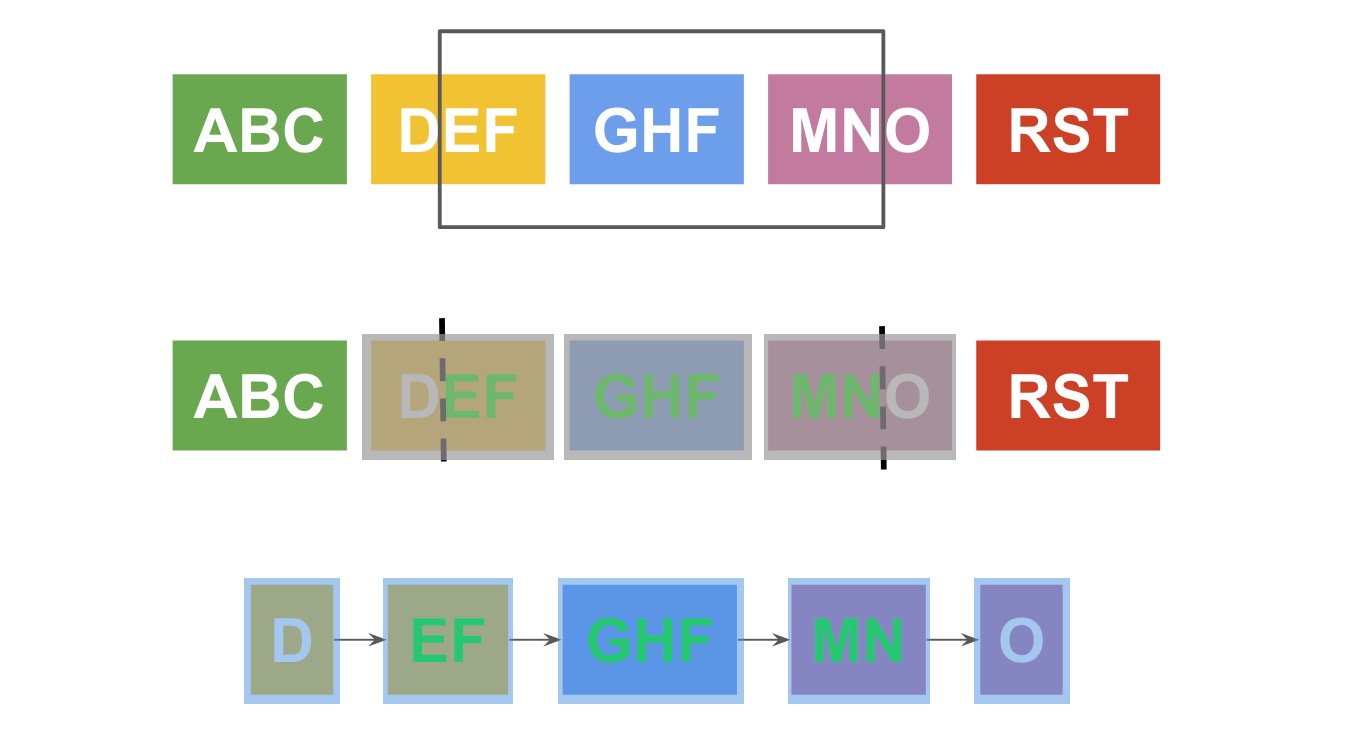
其中浅灰色层覆盖的节点为 oldNodes 数组;浅蓝色层覆盖的节点为 newNodes 数组。得到这两个数组后,首先对 oldNodes 数组中的节点进行操作,通过 attachedObject 属性得到 CodeMirror.TextMarker 对象,调用 clear() 方法,取消先前设置的 class。然后对 newNodes 数组中的节点,通过 markText 方法设置相应的 class。
👇下面列几个在这个方法中比较关键(链表优化)的处理:
1. mergeNodesWithSameAnnotations_
通过 wrapOperation_ (span, operationFn) 回调函数 operationFn 会生成一小段新的链表 var newSegment = operationFn(res.startPos, res.start),得到这段新链表段后,需要对其进行一个预处理,合并其中节点富文本属性 annotation 相同的节点,这个过程调用 mergeNodesWithSameAnnotations_ 方法
2. 存在 pred 或者 succ 节点时的判断
考虑如下这种情况: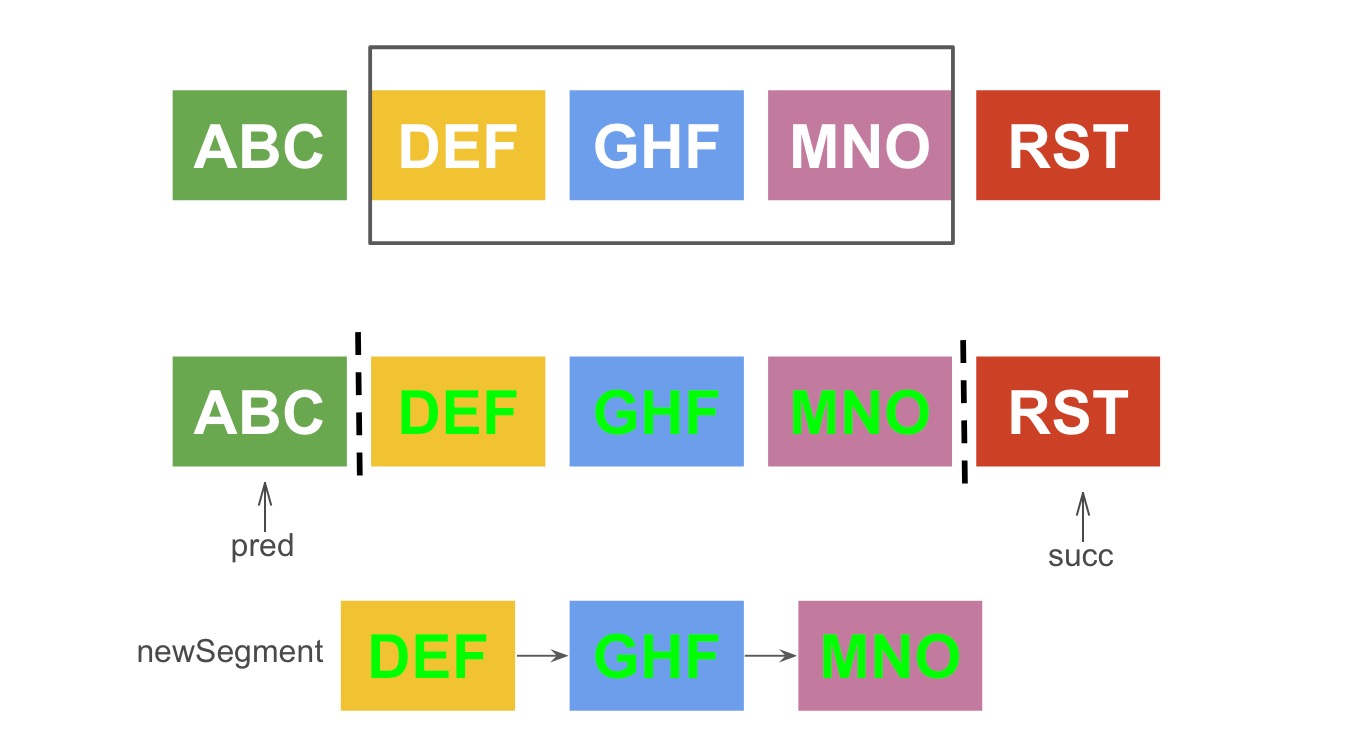
对中间三个节点进行更新操作,那么由于选择的文本区间边界正好处于链表的节点边界,所以 pred 和 succ 节点都不为空,那么此时需要进行两个判断:
pred节点和newSegment的首节点判断富文本属性annotation是否相同;若相同,说明pred节点和newSegment的首节点可以合并,那么需要将pred节点纳入oldNodes数组- 同理,
succ节点和newSegment的最后一个节点也需要执行如上逻辑的判断
|
|
查询操作
AnnotationList 类中也提供了两个链表查询方法,根据 pos 位置信息或者 span 指定文本区间查询链表节点信息,基本上都是遍历链表的操作,此处不详述,直接参考源码即可。
思考
AnnotationList 单链表结构执行操作的效率比较低,所有操作的算法复杂度都是 O(n),这个链表长度会随着文章长度,富文本属性设置操作的增加而变长。优化的方向是,将链表结果改造成树状结构。这部分优化内容在文章 SharedPen 之区间树优化 进行了详细介绍,欢迎前往阅读。🎏